Connect storage, drives, and databases into an AI-native workspace. Preserve provenance, enforce residency, and keep every conclusion traceable.
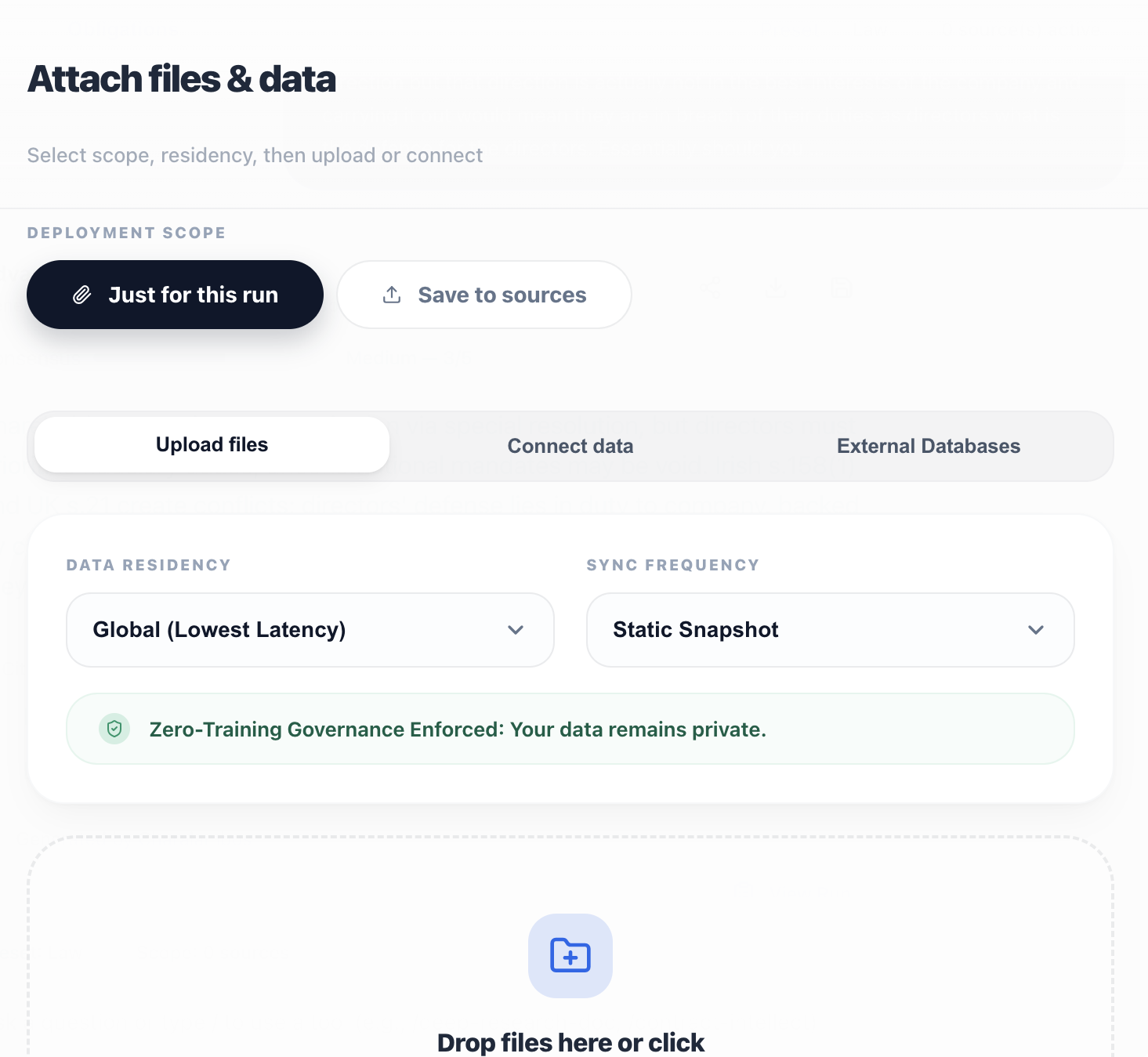
Secure connectors for AI workloads. Enforced residency. Full lineage on every retrieval.
Read-scoped adapters for S3, SharePoint, and Google Drive that power AI without model training.
Pin sources to EU/UK/US with policy-based routing, retention, and deletion tuned for AI workflows.
Every retrieval is logged and cited — source → query → AI answer — ready for audit and review.
Honor existing roles and groups so your AI assistant can only see what the user is allowed to see.
Every retrieval. Every AI claim. Traceable and controlled.
Mirror roles and approvals so LLMs only use data that users are already permitted to see.
Source → usage → output with timestamps, prompts, and reviewers captured for every answer.
Geographic processing, legal-hold aware retention, and deletion policies for your data plane.
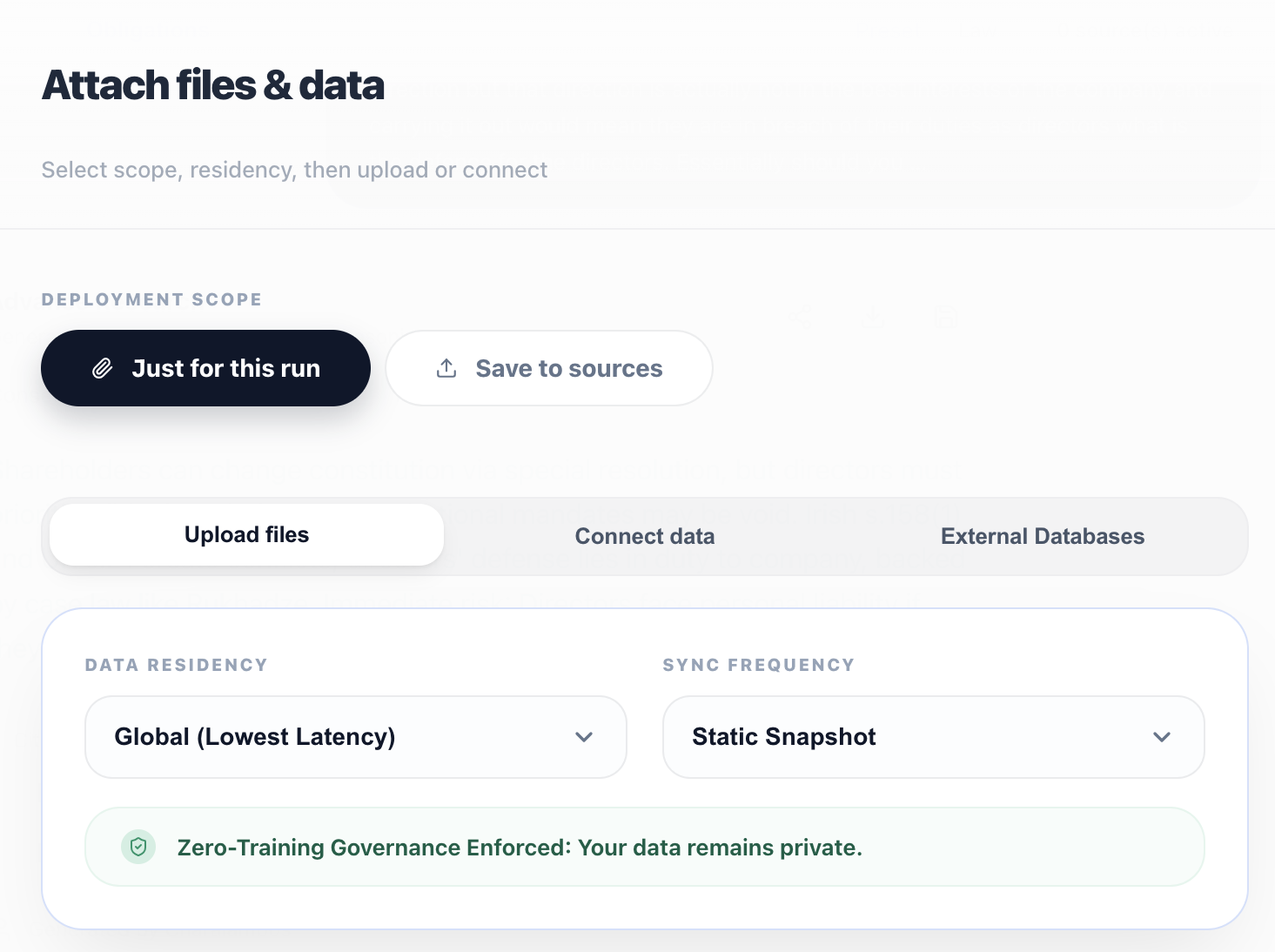
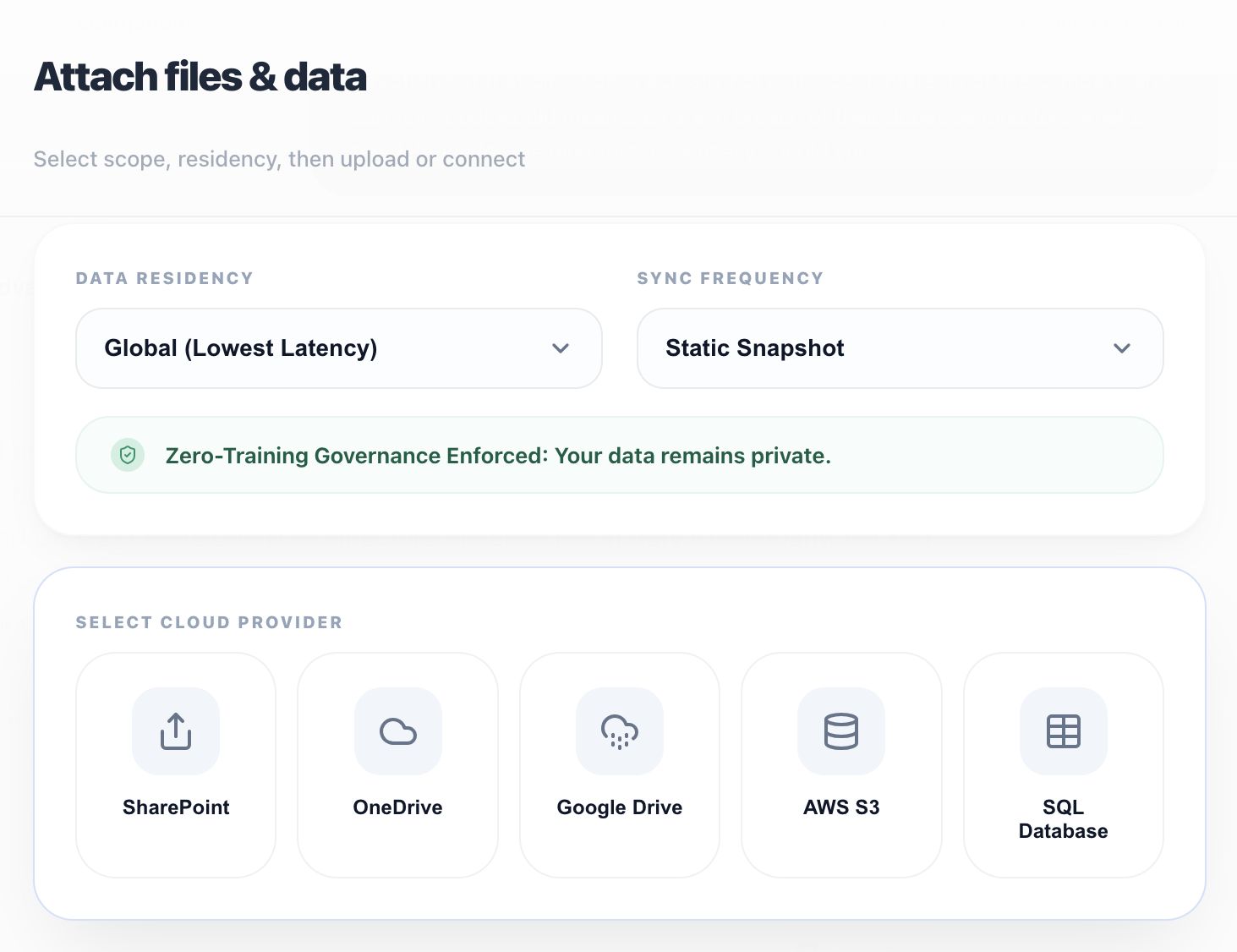
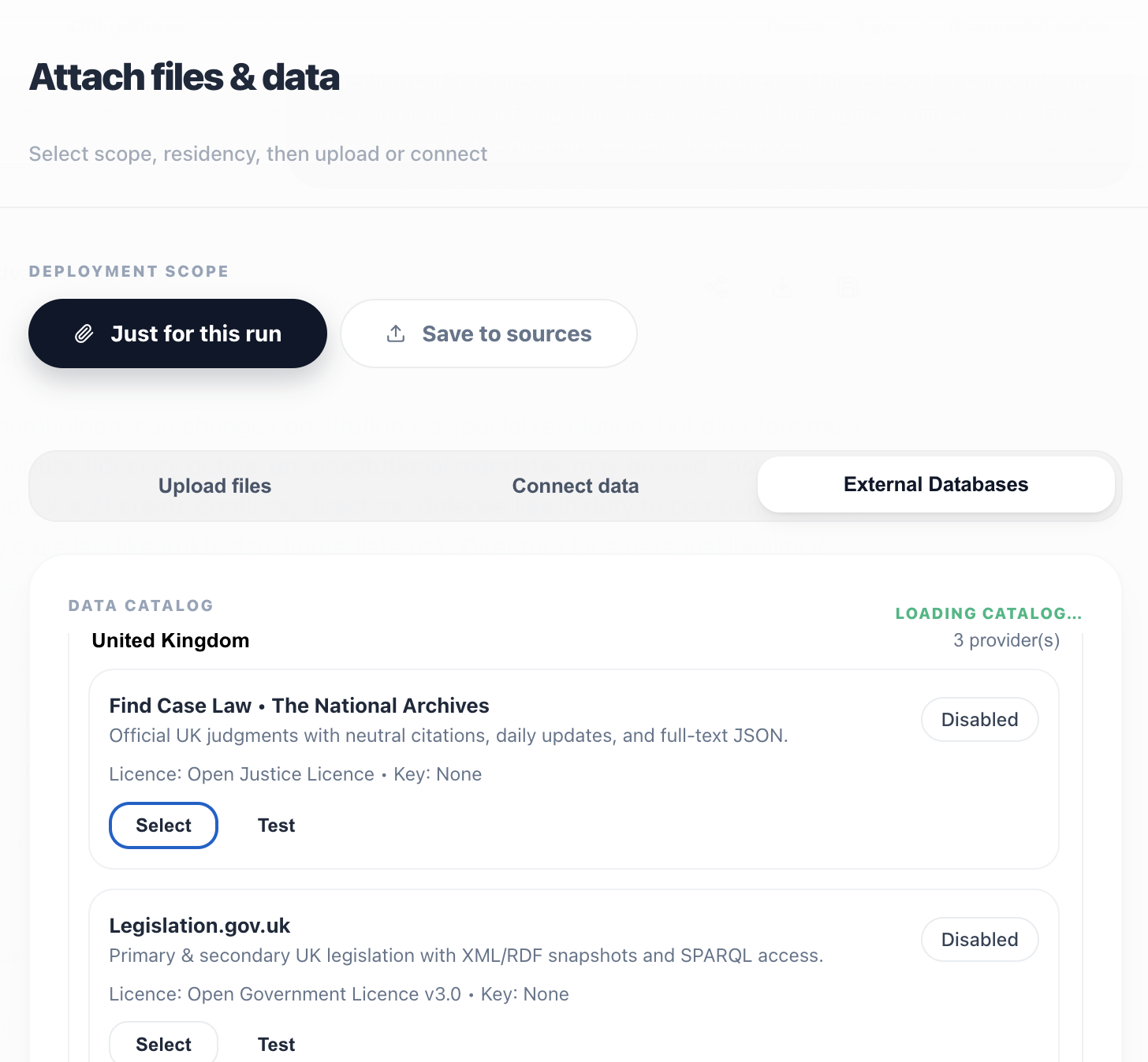
Policy-based routing for AI workloads in EU/UK/US or custom regions.
Log every retrieval with timestamps, requesters, and model context.
Click through from any AI claim to the underlying documentation.

Connect real systems under residency, RBAC, and lineage controls. Evaluate traceability and review workflows on your own data.