LangChain, CrewAI, AutoGPT, and custom agents, every step audited. Xybern validates reasoning chains and flags autonomous risk before outputs reach your users.
Full visibility into every agent decision.
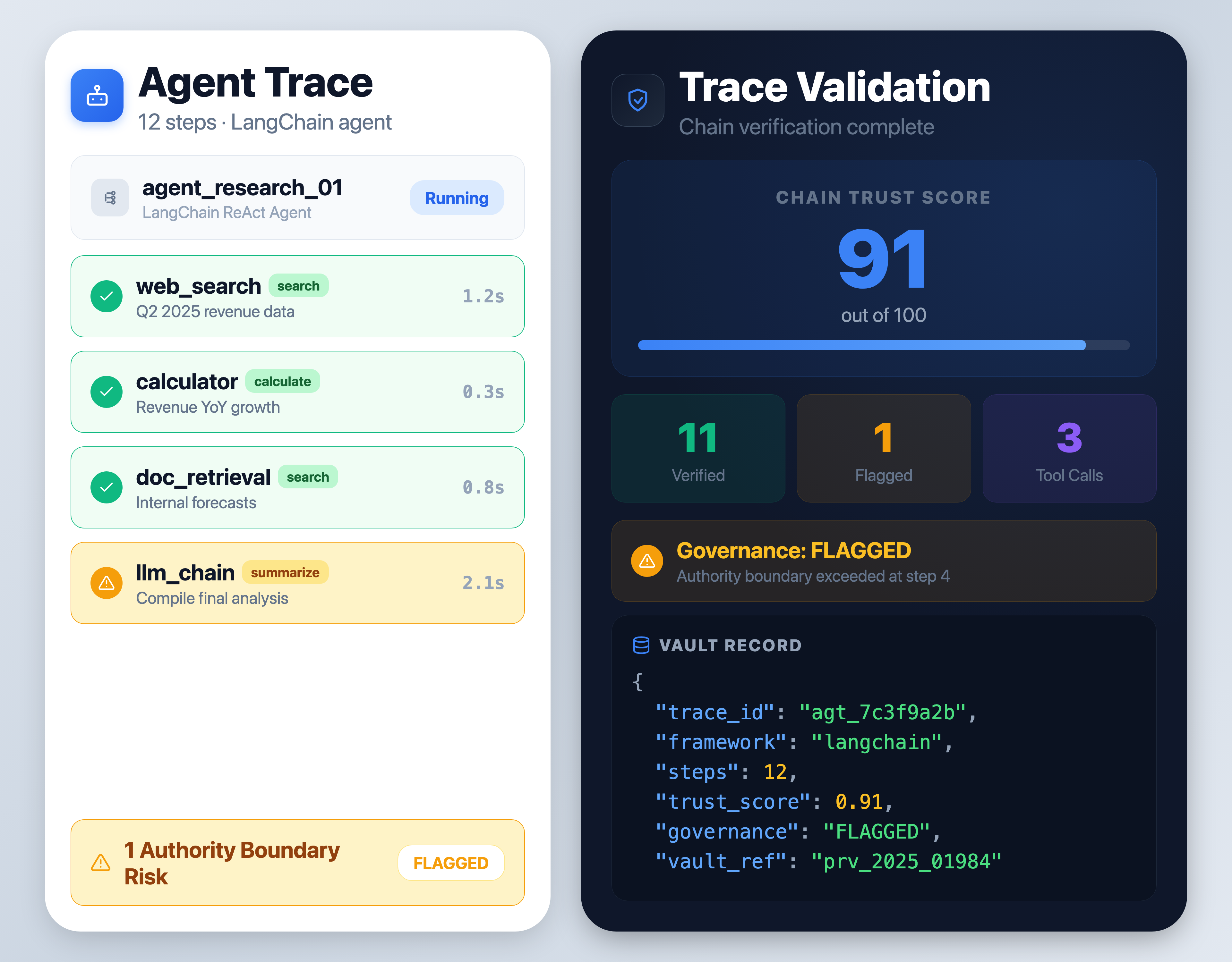
Integrates with any agent framework. Trace tool calls, reasoning steps, and output chains.
Every agent decision is decomposed into individual steps. Each step verified independently.
Flag when agents exceed authority, make unsupported claims, or bypass governance rules.
Xybern intercepts each step in the agent execution chain before outputs reach the user.
The agent runs its task, tool calls, reasoning steps, and intermediate outputs are all captured in real time.
Every decision point is decomposed and verified against evidence sources and governance rules.
The full reasoning chain receives a composite trust score. Risk flags are raised for any governance violations.
{
"trace_id": "agt_7c3f9a2b",
"framework": "langchain",
"steps": 12,
"tool_calls": ["search", "calculate", "summarize"],
"reasoning_chain": "verified",
"trust_score": 0.91,
"risk_flags": ["authority_boundary"],
"governance": "FLAGGED"
}Every dimension of agent behaviour, captured and verified.
Every external tool invocation is logged with inputs, outputs, and execution time.
The full chain-of-thought is captured, decomposed, and verified against evidence.
All intermediate results between steps are recorded for forensic replay.
The agent conclusion is trust-scored and checked against governance rules.
From invisible agent decisions to full governance coverage.
A single POST to /api/v1/verify/agent validates the entire agent decision chain in real time.
// Request
{
"framework": "langchain",
"agent_id": "agent_research_01",
"trace": {
"steps": 12,
"tool_calls": ["search", "calculate"],
"output": "The quarterly revenue..."
}
}
// Response
{
"trace_id": "agt_7c3f9a2b",
"trust_score": 0.91,
"steps_verified": 11,
"steps_flagged": 1,
"risk_flags": ["authority_boundary"],
"governance": "FLAGGED",
"vault_ref": "prv_2025_01984"
}Deploy runtime enforcement across your entire agent infrastructure. Full control from day one.